
在 AI 项目越来越普及之后,很多团队第一次租用 GPU 资源时,都会碰到同一个问题:到底该选 GPU 云服务器,还是直接上裸金属 GPU 服务器?两者都能跑训练和推理,但成本结构、资源控制权和后续扩展方式其实差很多。
如果这个问题只看单价,很容易选错。因为你真正要衡量的,不只是“每小时多少钱”,而是:
- 资源利用率高不高
- 训练周期长不长
- 推理业务是否长期在线
- 团队是否需要独占资源
这篇文章就从训练、推理和长期成本三个角度,说明 GPU 云服务器与裸金属 GPU 服务器的分界线。
一、GPU 云服务器的优势,在于更轻的启动成本
GPU 云服务器通常更适合这些场景:
- 先验证模型能不能跑
- 阶段性训练任务
- 团队还在试错,不确定长期规模
- 需要更灵活地启停资源
对刚起步的团队来说,GPU 云服务器的价值不是“绝对便宜”,而是试错成本更低。你不用一开始就承担完整独占资源的预算,可以先把数据、框架、训练流程跑通。
二、裸金属 GPU 服务器的优势,在于长期独占与稳定性
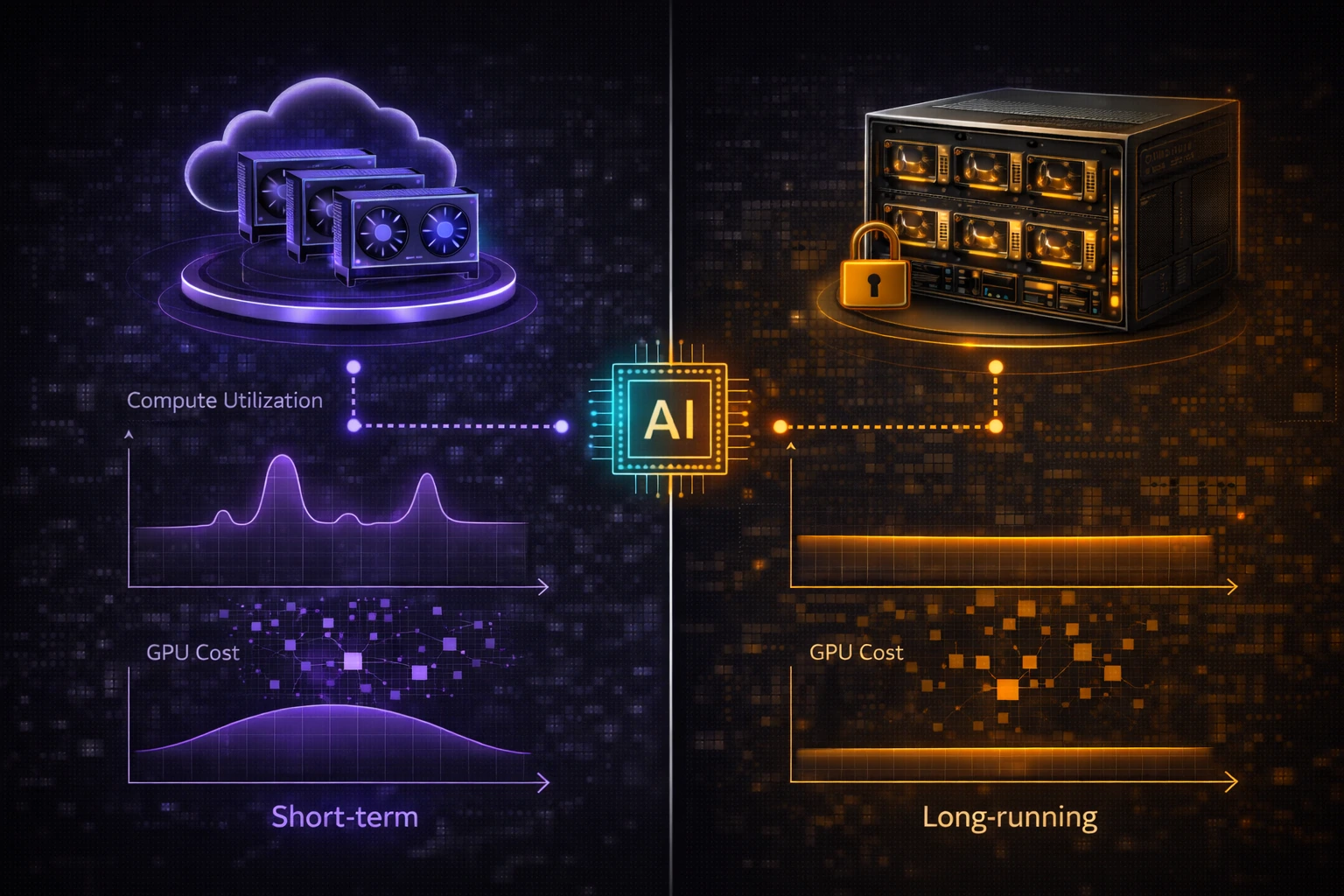
如果你的训练任务长时间持续,或者推理服务本身就是核心业务,那么裸金属 GPU 服务器的价值会变得明显。因为这时候你更在意:
- GPU 资源独占
- 长时间稳定负载
- 本地存储与数据吞吐
- 多任务并发时的可控性
对长期在线的推理服务、持续训练集群或资源占用很高的项目来说,独占资源通常比灵活开关更重要。
三、训练场景怎么选:看训练周期和利用率
训练场景里,最关键的问题是“GPU 会不会长时间保持高利用率”。
更适合 GPU 云服务器的训练
- 实验性训练
- 小批量模型验证
- 阶段性微调任务
- 预算敏感且工作负载不连续
更适合裸金属 GPU 的训练
- 长周期训练
- 多轮反复迭代
- 对显存、吞吐和稳定性要求更高
- 团队已经明确会长期占用 GPU 资源
简单说:如果 GPU 大部分时间并不会满负载运行,云服务器更灵活;如果 GPU 会长期吃满,裸金属通常更划算。
四、推理场景怎么选:看在线时长和稳定性要求
推理和训练不同。很多推理业务的特点不是短时爆发,而是长期在线、请求持续稳定。
如果你的推理服务:
- 需要 24/7 在线
- 对响应稳定性比较敏感
- 后端还要配合缓存、队列或业务接口
那么裸金属 GPU 服务器通常更有吸引力,因为它更适合做长期承载。反过来,如果推理需求本身是阶段性的、临时活动型的,云服务器会更灵活。
五、很多人算错成本,是因为只算了租金
真正的 GPU 成本,不只包括机器价格,还包括:
- GPU 空闲时间浪费
- 数据迁移和存储成本
- 运维和调度复杂度
- 中断或迁移的隐性代价
如果团队经常切换任务、暂停训练、临时开实验,那么 GPU 云服务器虽然单价不一定最低,但整体成本可能更优。
如果业务长期稳定运行,独占资源反而会让总成本更可控。
六、什么时候该从云 GPU 走向裸金属 GPU
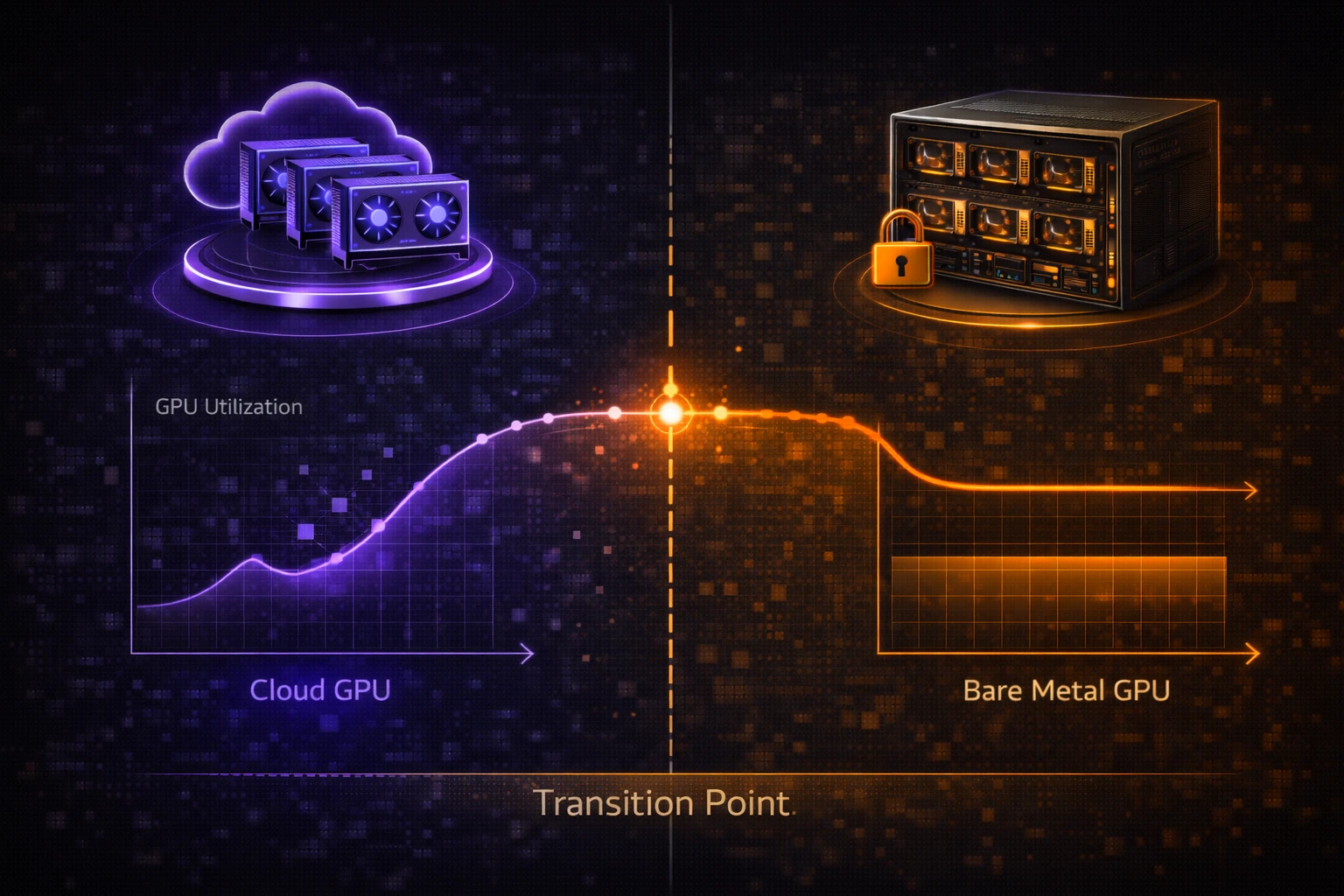
下面这些信号,通常说明你已经接近裸金属阶段:
- GPU 长期高利用率
- 训练任务越来越连续
- 推理服务已经成为正式业务
- 更在意稳定独占,而不是灵活启停
- 团队已经具备更成熟的环境管理能力
如果这些信号已经出现,再继续完全依赖弹性云 GPU,成本和管理复杂度都可能开始失衡。
七、不要忽略产品形态背后的团队能力
GPU 选型不是只看模型,也要看团队:
- 是否有人负责环境维护
- 是否能处理驱动、依赖和运行时问题
- 是否需要更强的资源隔离
- 是否有长期数据存储和任务调度要求
如果团队仍在早期验证阶段,先用 GPU 产品页 对照现有能力做判断,比一上来追求“最大算力”更现实。
如果你还在判断资源形态边界,也可以对照 美国独立服务器适用场景 一起看,把“算力资源”和“长期承载需求”放在同一张表里判断。
如果你的训练链路还会依赖站点后台、数据下载或跨境访问路径,也可以顺手参考 服务器栏目 的相关内容,把算力资源和整体基础设施一起评估,而不是只盯着单块 GPU 的账单。
如果你的项目后续还会把 GPU 训练、数据存储、推理接口和业务系统一起串起来,那就不能只看单台 GPU 机器的租金。更完整的做法,是把数据搬运、任务调度、环境维护和持续在线成本全部一起算进来,这样才知道自己到底是在买“灵活性”,还是在买“长期确定性”。
对于预算有限的团队来说,最稳妥的顺序通常是:先用云 GPU 完成验证,再在利用率稳定升高后考虑裸金属;而不是一开始就把预算压在最高规格方案上,结果大量资源长期空闲。
如果你目前的重点还只是验证模型是否可行,那么先把训练流程、数据准备和推理链路跑顺,通常比提前锁定长期硬件更重要。等到项目进入稳定迭代阶段,再去重新评估裸金属 GPU,判断会更准确,也更接近真实业务成本。
如果后续模型规模持续增长、显存需求越来越稳定、训练窗口也越来越固定,那么再把裸金属 GPU 纳入长期方案,通常会比一开始拍脑袋选定更合理。
结语
GPU 云服务器和裸金属 GPU 服务器的真正分界线,不在宣传词,而在你的任务利用率、在线时长和资源独占需求。
对大多数团队来说,先用云 GPU 完成验证,再在长期高利用率阶段转向裸金属,会比一开始重投入更稳妥。