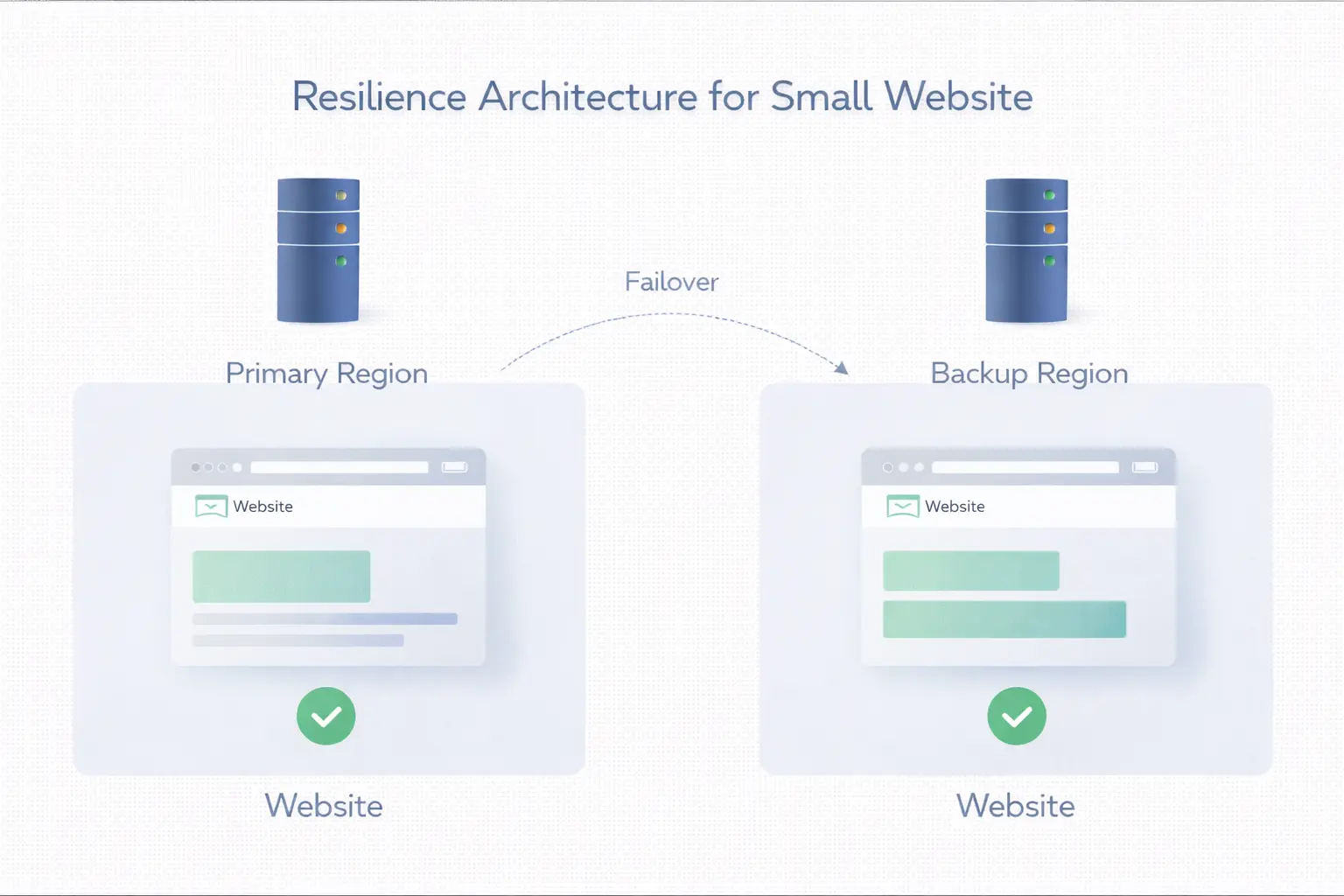
过去很多站长听到“多地区部署”就会觉得那是大厂才玩得起的架构,预算、团队和系统复杂度都不是中小站点能碰的东西。这个印象并不完全对。到了 2026 年,真正变得更现实的不是所有站点都去做大规模多活,而是越来越多中小团队开始意识到:容灾不一定非要昂贵,也不一定非要一次做满。
多地区部署对中小站点真正有价值的地方,在于它能把“单点故障后只能等恢复”这件事,变成“至少还能留一条可继续服务的路径”。对预算有限的团队来说,关键不是模仿大厂,而是先做出最小可用的分层:哪些内容值得复制,哪些入口值得切换,哪些数据必须优先保护。
相关的主机与节点规划思路,可以顺带看 HostEase 的 服务器文章。真正务实的容灾路线,从来不是一步到位,而是先用有限预算守住最重要的业务连续性。
先说结论:中小站点做多地区部署,重点不该是“全同步”,而该是“先保住关键路径”
如果预算和团队能力都有限,最不现实的做法就是一开始追求所有业务、所有数据、所有节点都完全一致。这样做不仅贵,也很难维护。对大多数中小站点来说,真正有意义的是先识别关键路径:主页、产品页、文档页、结账页、登录页或联系入口,哪些一旦掉线就会立刻伤害业务,就先保哪些。
也就是说,低成本容灾首先是优先级问题,而不是节点数量问题。优先级一清楚,很多原本看起来很贵的事情,反而会变得可拆解。
为什么现在中小站点也值得认真看多地区部署
1. 业务越来越依赖持续在线
很多站点过去掉线几个小时影响有限,但现在用户获取、内容传播、客户咨询和转化路径都更连续。一旦单点失效,损失会比以前更直接。
2. 节点和基础设施组合比过去更灵活
现在更常见的不是“买一整套超大架构”,而是把主节点、备用节点、对象存储、CDN 和 DNS 切换组合起来,先做出足够实用的容灾层。
3. 容灾可以按阶段推进
中小团队不需要一步到位做成大规模双活。先从静态内容容灾、文档镜像、备节点接管或简单切换做起,已经比单点完全裸奔强很多。
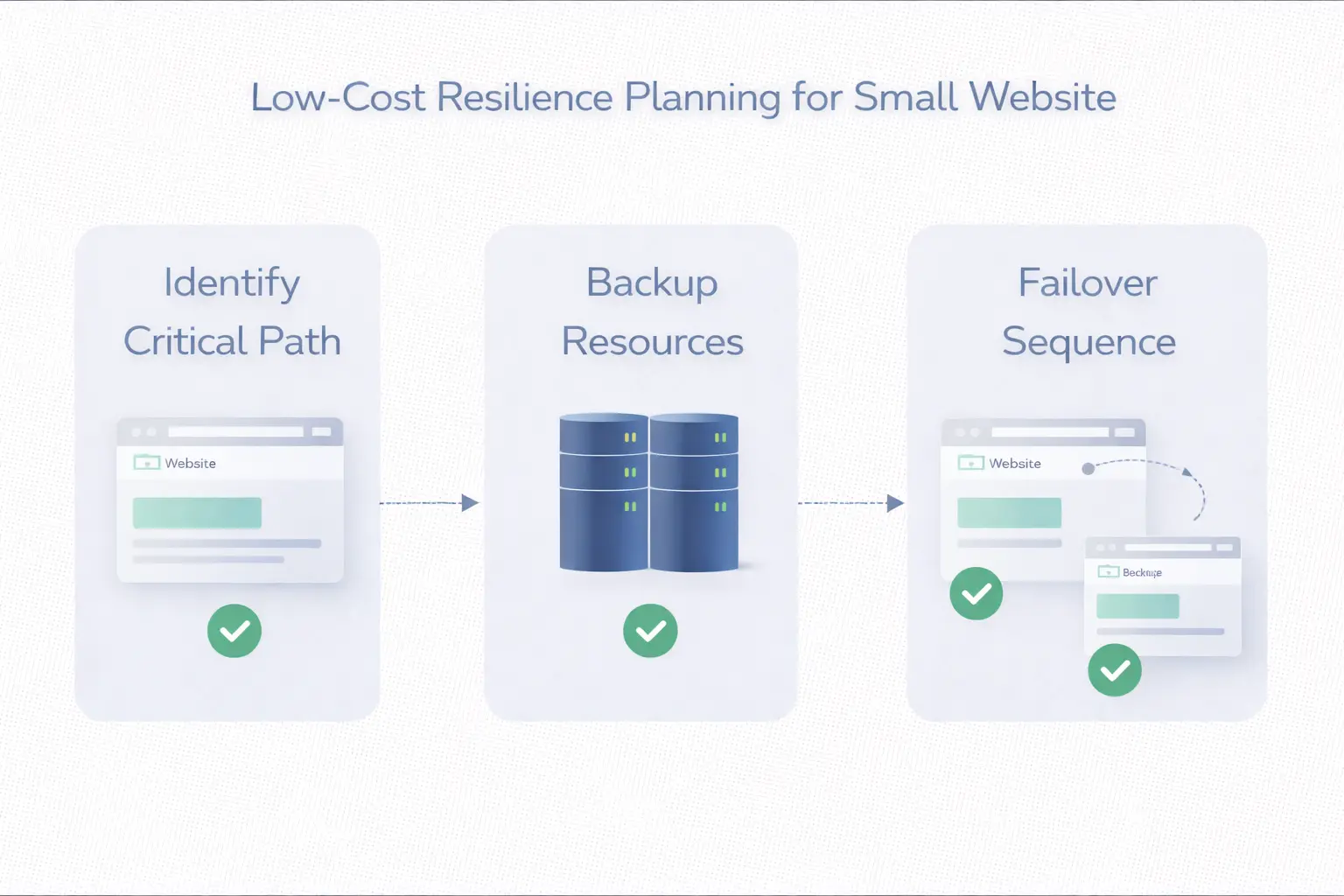
低成本容灾最常见的 3 种现实做法
第一种,主站加备用节点。 平时只让备用节点保持基础可切换能力,真正出故障时再接管部分关键流量。这个思路最接近“低成本起步”。
第二种,动态和静态分层。 程序主入口放在主节点,静态资源、图片、文档和下载放到更容易分发的位置。这样即便主站波动,至少一部分内容还能保持可访问。
第三种,DNS 和 CDN 配合切换。 不一定要把所有逻辑都复制到多个地区,但至少要让入口切换不至于全靠人工现场救火。
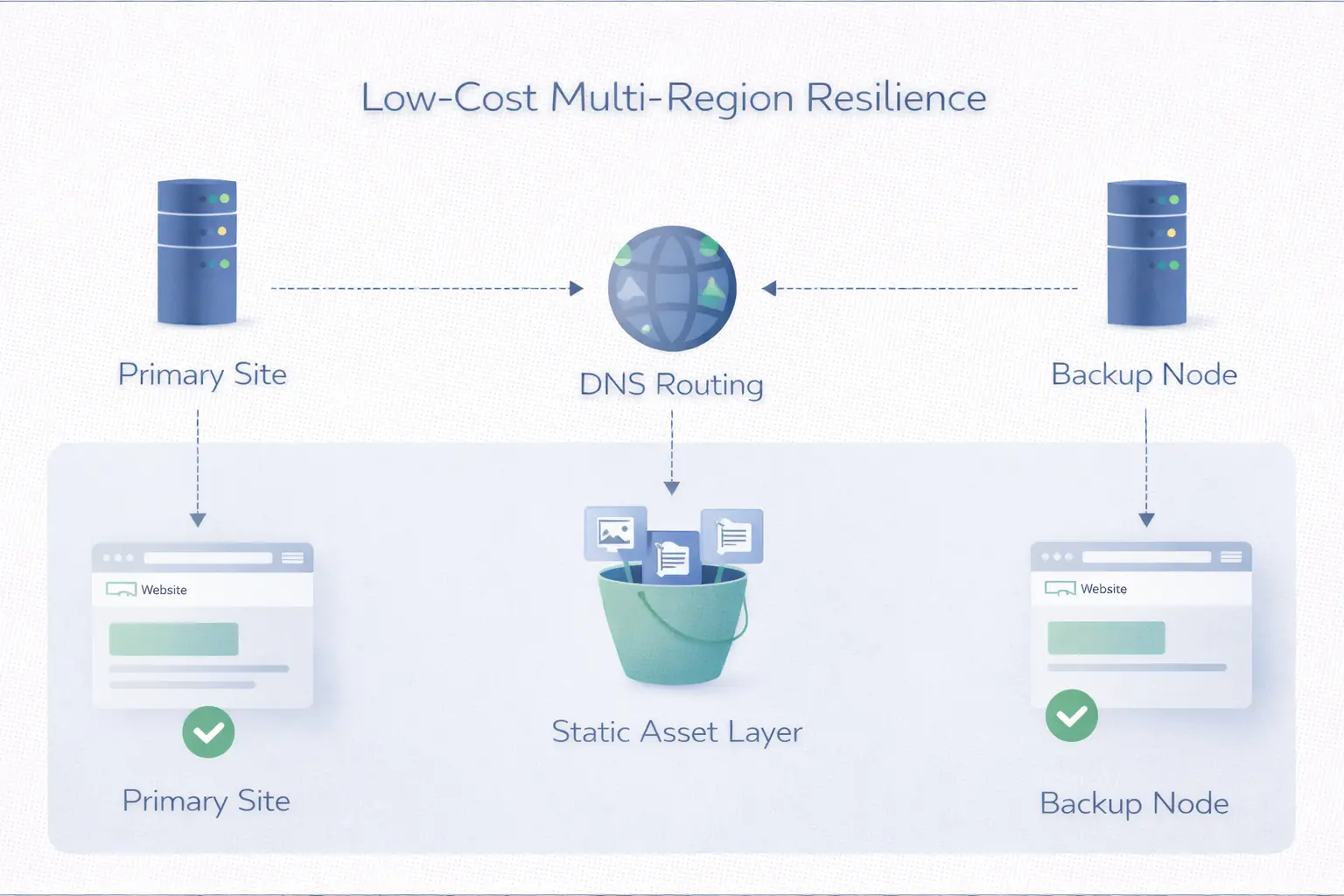
最容易犯的错:把多地区部署理解成“必须做得很重”
很多团队一想到多地区,就自动脑补成昂贵、复杂、同步困难的多活平台。结果不是直接放弃,就是做了一个根本维护不了的重方案。其实低成本容灾最重要的恰恰是做减法:哪些必须先保,哪些可以延后,哪些只需要备用,不需要常态全开。
另一种常见误判是,只复制机器,不梳理切换顺序。这样即便有多个节点,真出问题时还是很乱。容灾不是机器数量游戏,而是切换路径是否清楚。
中小团队更务实的落地顺序
先识别关键页面和关键业务;再确定哪些资源可以低成本复制,哪些数据要重点保护;然后设计最简单可执行的切换路径,包括 DNS、CDN、备用节点和通知顺序。只要这三步做出来,容灾能力就已经比纯单点运行强很多。
后面如果预算增加,再逐步增强同步、监控和自动切换,而不是一开始就把所有复杂度都买进来。这种阶段化路线更符合中小站点的现实。
很多中小团队真正需要的,不是像大厂那样全天候多活,而是在主节点失效时还能保住基本访问、核心页面和对外联系入口。只要先把这件事做到位,容灾就已经从“完全没有”变成“至少可切换”,业务风险会下降很多。
所以低成本容灾的重点,从来不是买多少节点,而是切换路径有没有写清楚。路径清楚了,节点数量反而可以慢慢增加;路径不清楚,节点再多也只会在故障时继续手忙脚乱。
这也是为什么很多中小站点真正值得先做的,是把容灾当成业务连续性练习,而不是技术展示。哪怕只是备用首页、备用文档和备用联系入口,也比完全没有后路强得多。容灾的第一步不是做全,而是先别只剩单点。
只要团队先接受这一点,多地区部署就不会再显得遥不可及。它可以从最小方案开始,先解决“出事后还有没有第二条路”这个问题,再慢慢决定是否继续往更复杂的同步和自动切换走。
这也是中小站点最该先建立的容灾心态:先让关键服务有退路,再谈更复杂的连续性优化。只要这个顺序对了,预算再有限,也能一步步把容灾能力做出来。
很多时候,一次真正有价值的容灾演练,甚至不需要动太多技术细节,而是先验证几个现实问题:备用入口能不能打开、关键页面能不能被替代访问、团队在十分钟内能不能完成切换、对外通知有没有固定顺序。只要这些动作做过一遍,纸面上的“有备用节点”才开始接近真实可用。
对中小团队来说,这种可执行性比架构名词更重要。因为真正决定故障时能不能撑住的,通常不是方案听起来多先进,而是团队有没有把最小切换路径提前走通。预算有限时,先把这件事做扎实,往往比继续堆复杂度更有效。
先有退路,再谈完美,这就是低成本容灾最现实的逻辑。
结语:低成本容灾不是做得像大厂,而是先别只剩单点
多地区部署不再是大厂专利,因为中小站点现在也越来越需要基本的业务连续性。真正重要的,不是一次做成多复杂,而是先从“完全没有后路”变成“至少还有一条路能走”。
只要先把关键路径保住,把切换顺序写清楚,再用更有限的预算搭出最小容灾层,多地区部署就不再只是大厂术语,而会变成很多中小站点都用得上的现实方案。