当你的网站日访问量突破 10 万 PV,单台数据库服务器开始频繁出现慢查询告警,这时候如何在不大幅改动应用代码的前提下提升数据库的读写能力?MySQL主从复制(Replication)配合读写分离(Read-Write Splitting)是目前最成熟、成本最低的方案之一。本文将从原理出发,带你完成主从复制配置、读写分离搭建,以及故障切换方案的落地。
为什么需要 MySQL 主从复制
在单机 MySQL 架构下,所有读写请求集中在一台服务器上。随着业务增长,你会遇到两个核心瓶颈:
第一个是读性能瓶颈。电商类网站在促销期间,商品详情页、订单查询等读操作可能占到总请求的 80% 以上。单台服务器的 CPU 和内存资源有限,大量并发读请求会导致响应时间从毫秒级退化到秒级。数据库性能与转化率直接相关——每多 1 秒延迟,转化率可能下降 7%。
第二个是可用性风险。单机架构没有冗余,一旦服务器硬件故障或磁盘损坏,整个业务将完全中断。可以参考备份与容灾策略来理解为什么多副本存储对业务连续性至关重要。
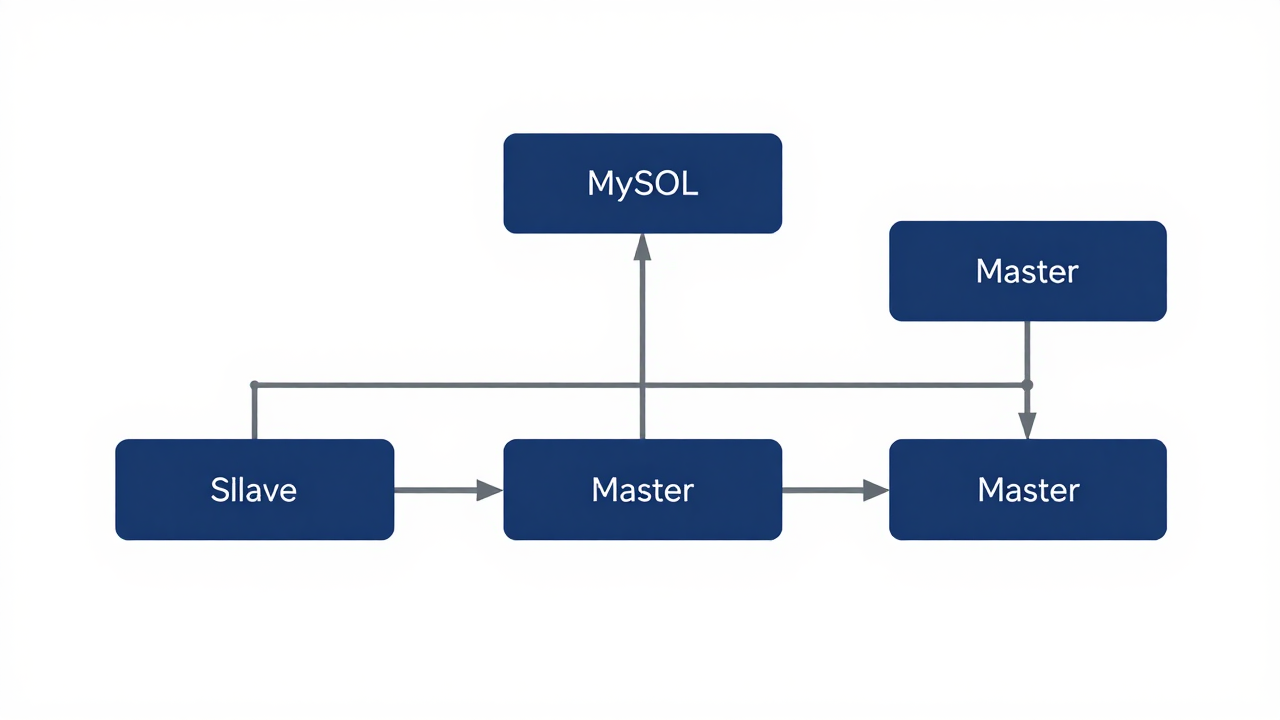
MySQL主从复制通过将数据从主库(Master)异步复制到一个或多个从库(Slave),实现数据的多副本存储。读请求分散到从库处理,主库只承担写入操作,整体吞吐量可提升 2-5 倍。
主从复制的工作原理
在动手配置之前,先理解 MySQL 复制的三个核心线程。
Binlog Dump 线程运行在主库上。当从库发起复制请求时,主库会创建这个线程,将二进制日志(binlog)中的变更事件发送给从库。
I/O 线程运行在从库上。它负责连接主库,接收 binlog 事件并写入本地的中继日志(Relay Log)。中继日志相当于从库端的临时缓存区。
SQL 线程同样运行在从库上。它读取中继日志中的事件并逐条重放,从而实现数据同步。MySQL 5.7 之后支持多线程复制(MTS),可以并行回放不同数据库的事务,显著降低复制延迟。
从库通过 `CHANGE MASTER TO` 语句记录主库的连接信息,并用 `START SLAVE` 启动复制。
配置前的环境准备
正式配置前,需要确认以下条件:
主从复制配置实战
以下配置基于 MySQL 8.0,使用 GTID(全局事务标识符)模式。GTID 让从库可以自动定位复制位点,无需手动指定 binlog 文件名和偏移量。
第一步:配置主库
编辑主库的 MySQL 配置文件(通常位于 `/etc/my.cnf`),在 `[mysqld]` 段添加:
server-id = 1
log-bin = mysql-bin
binlog_format = ROW
gtid_mode = ON
enforce_gtid_consistency = ON
binlog_expire_logs_seconds = 604800`server-id` 是主库的唯一标识,集群内每台实例必须不同。`binlog_format = ROW` 记录行级变更,比 STATEMENT 模式更安全。修改完成后重启 MySQL:
sudo systemctl restart mysql创建复制专用账号:
CREATE USER ‘repl_user’@’%’ IDENTIFIED BY ‘YourSecurePassword’;
GRANT REPLICATION SLAVE ON . TO ‘repl_user’@’%’;
FLUSH PRIVILEGES;第二步:配置从库
编辑从库的配置文件:
server-id = 2
relay-log = relay-bin
read_only = ON
gtid_mode = ON
enforce_gtid_consistency = ON`read_only = ON` 防止应用误写从库。多台从库的 `server-id` 递增设置。重启后配置复制指向主库:
CHANGE MASTER TO
MASTER_HOST = ‘主库IP’,
MASTER_PORT = 3306,
MASTER_USER = ‘repl_user’,
MASTER_PASSWORD=’*‘,
MASTER_AUTO_POSITION = 1;
START SLAVE;
第三步:验证复制状态
在从库上执行:
SHOW SLAVE STATUS\G确认 `Slave_IO_Running` 和 `Slave_SQL_Running` 均为 `Yes`,`Seconds_Behind_Master` 为 0 或接近 0。在主库插入测试数据后从库查询验证同步即可。
搭建读写分离架构
主从复制解决了数据同步,真正的性能提升来自读写分离——写请求走主库、读请求走从库。
方案一:基于 ProxySQL 的中间件代理
ProxySQL 位于应用和数据库之间,自动将 SELECT 语句路由到从库,INSERT/UPDATE/DELETE 路由到主库:
INSERT INTO mysql_servers (hostgroup_id, hostname, port) VALUES (10, ‘主库IP’, 3306);
INSERT INTO mysql_servers (hostgroup_id, hostname, port) VALUES (20, ‘从库IP’, 3306);
INSERT INTO mysql_query_rules (rule_id, active, match_pattern, destination_hostgroup)
VALUES (1, 1, ‘^SELECT .* FOR UPDATE$’, 10),
(2, 1, ‘^SELECT’, 20);
LOAD MYSQL SERVERS TO RUNTIME;
LOAD MYSQL QUERY RULES TO RUNTIME;
SAVE MYSQL SERVERS TO DISK;
SAVE MYSQL QUERY RULES TO DISK;
应用的数据库连接指向 ProxySQL 的监听端口(默认 6033),读写分离逻辑由 ProxySQL 自动处理,应用代码无需修改。
方案二:应用层代码路由
在应用连接层实现简单路由,以 Python SQLAlchemy 为例:
from sqlalchemy import create_engine
master_engine = create_engine(‘mysql+pymysql://user:*@主库IP/db’)
slave_engine = create_engine(‘mysql+pymysql://user:*@从库IP/db’)
def get_connection(readonly=False):
return slave_engine.connect() if readonly else master_engine.connect()
这种方式零依赖但需修改应用代码,适合小型项目。对于 WordPress 类 CMS,建议使用 ProxySQL 方案。
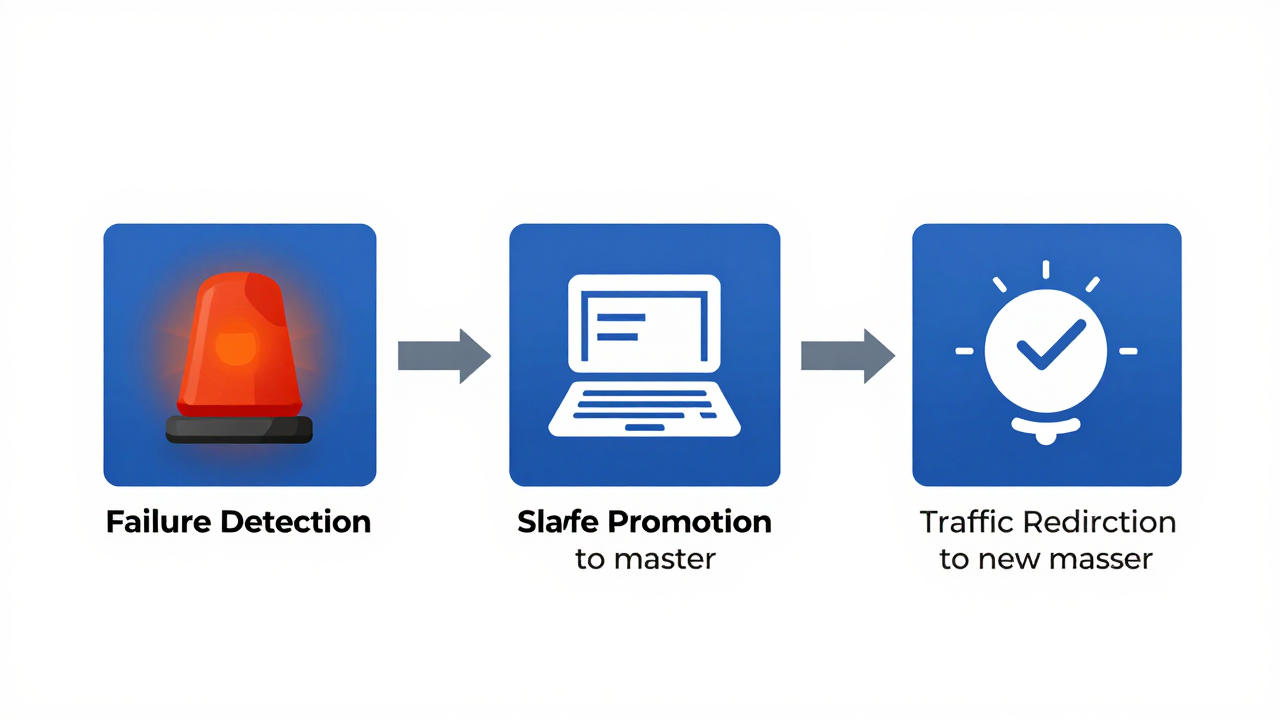
故障切换方案
读写分离解决了性能问题,但主库宕机后写入仍会中断。下面介绍三种故障切换方案。
方案一:手动切换(小型项目)
主库故障时,DBA 手动将从库提升为新主库:
STOP SLAVE;
RESET SLAVE ALL;
SET GLOBAL read_only = OFF;
SELECT @@gtid_executed;然后更新 ProxySQL 配置,将提升的从库加入主库组。RTO(恢复时间目标)通常在 5-15 分钟。
方案二:基于 MHA 的半自动切换
MHA(Master High Availability)由 Manager 和 Node 组成。Manager 监控主库健康状态,检测到宕机时自动选择数据最新的从库进行提升。MHA 的核心优势在于数据补偿机制——主库宕机时可能存在未同步的 binlog 事件,MHA 会尝试从旧主库磁盘提取差异事件并应用到新主库。RTO 通常在 10-30 秒。
方案三:基于 Orchestrator 的自动拓扑管理
Orchestrator 是 GitHub 开源的拓扑管理工具,提供 Web 界面和灵活的拓扑感知能力。建议将 Orchestrator 与 ProxySQL 联动:Orchestrator 负责故障检测和拓扑调整,ProxySQL 负责流量路由。切换完成后通过回调脚本自动更新 ProxySQL 配置,实现端到端自动故障切换。
监控与运维要点
部署完成后,小团队可观测性实践中提到的监控思路同样适用于数据库运维。重点关注以下指标:
总结与下一步行动
MySQL主从复制 + 读写分离 + 故障切换是一套经过大量生产验证的数据库高可用方案。你只需要 2-3 台服务器就能搭建起具备读写分离和自动故障切换能力的数据库集群。
建议按以下路径推进:先从主从复制开始,验证数据同步正确性;然后引入 ProxySQL 实现读写分离,观察读性能提升;最后根据业务可用性要求选择故障切换方案。对于需要更高 SLA 保障的业务,可以考虑升级为 MySQL Group Replication 或 InnoDB Cluster。