
开篇:为什么你的 WordPress 总是出现 502 错误
502 Bad Gateway 错误是 WordPress 站点最常见的问题之一:页面突然无法访问,业务直接中断,且往往在高流量时段爆发。本文将提供完整的日志分析方法、容量评估标准和扩容方案,帮你彻底解决 502 错误。
502 错误的本质:网关为什么会超时
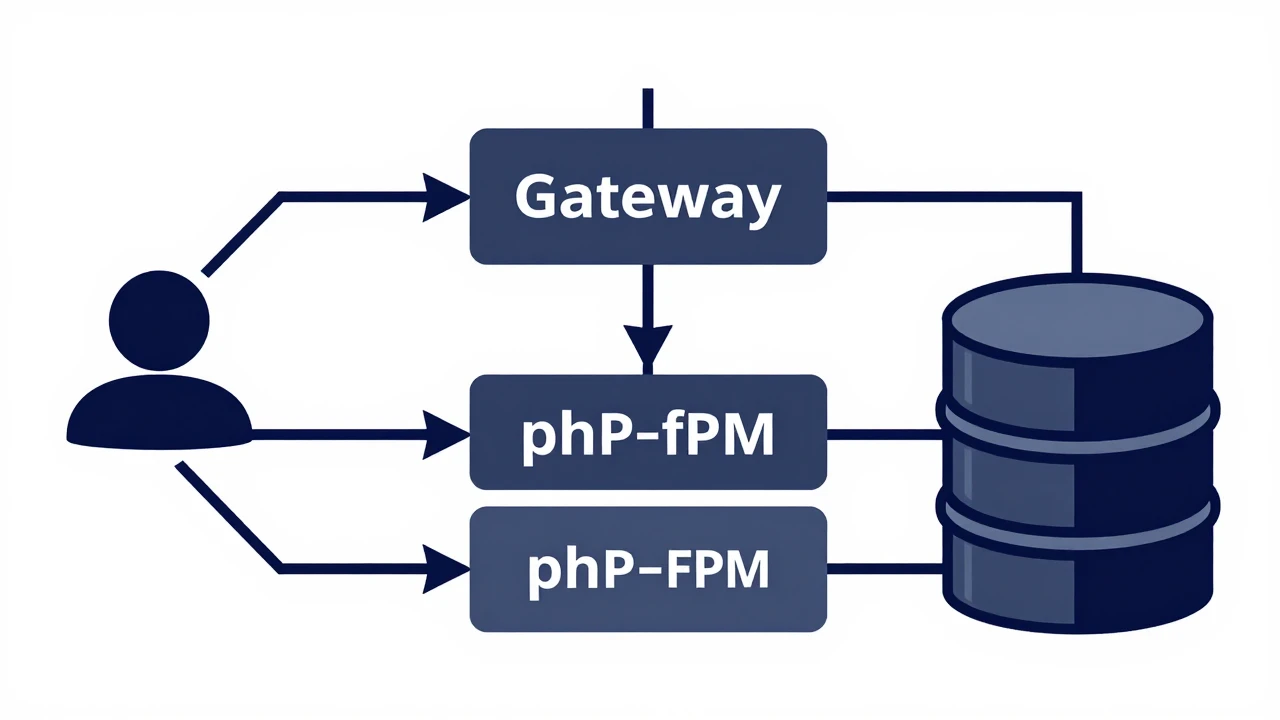
502 错误的全称是”502 Bad Gateway”,它表示作为网关或代理的服务器从上游服务器收到了无效响应。在 WordPress 环境中,典型的架构是:
用户请求 → Nginx/Apache(网关) → PHP-FPM → WordPress/MySQL
当 Nginx 或 Apache 作为反向代理时,如果 PHP-FPM 处理请求超时或崩溃,网关就会返回 502 错误。常见触发场景:PHP 进程池耗尽、脚本执行超时、内存不足被 OOM Killer 终止、MySQL 连接数达上限、磁盘 I/O 阻塞(网络带宽指数据传输速率,通常以 Mbps 或 Gbps 为单位)。
理解这些触发机制是有效排障的第一步。
日志定位:三步找到问题根源
第一步:确认 502 错误的时间分布
首先,统计 502 错误的发生时间和频率:
grep "502" /var/log/nginx/error.log | awk '{print $1, $2}' | cut -d: -f1 | sort | uniq -c
tail -100 /var/log/nginx/error.log | grep "502"
如果错误集中在特定时间段(如每天 10:00-11:00),可能与定时任务、流量高峰或备份作业相关。如果错误随机分布,则更可能是资源瓶颈或代码问题。
第二步:检查 PHP-FPM 日志
PHP-FPM 日志包含进程崩溃、内存溢出等关键信息:
tail -200 /var/log/php-fpm/error.log
grep -i "killed\|oom\|memory" /var/log/php-fpm/error.log
systemctl status php-fpm
如果看到”server reached max_children setting”警告,说明 PHP 进程池已耗尽。
第三步:分析系统资源日志
uptime # 系统负载
free -h # 内存使用
iostat -x 1 5 # 磁盘 I/O
mysql -e "SHOW STATUS LIKE 'Threads_connected';" # MySQL 连接数
系统负载持续高于 CPU 核心数即表示过载。
容量评估:你的服务器是否真的不够用
CPU 使用率评估
- 正常范围:40-60%
- 警戒线:持续超过 80%
- 危险线:持续超过 95%
内存使用评估
- 正常范围:PHP-FPM 单进程 50-100MB
- 警戒线:可用内存低于 500MB
- 危险线:频繁触发 swap 或 OOM
磁盘 I/O 评估
- 正常范围:iowait 低于 10%
- 警戒线:持续超过 20%
- 危险线:超过 50%
网络带宽(网络数据传输速率)评估
- 正常范围:带宽使用率低于 70%
- 警戒线:峰值接近带宽上限
- 危险线:持续饱和导致丢包
检查网络接口丢包统计:netstat -i 或 ip -s link。
扩容方案:从临时缓解到长期优化
方案一:优化现有配置(零成本)
PHP-FPM 优化:
; /etc/php-fpm.d/www.conf
pm = dynamic
pm.max_children = 50
pm.start_servers = 10
pm.min_spare_servers = 5
pm.max_spare_servers = 20
pm.max_requests = 500
request_terminate_timeout = 60s
Nginx 优化:
worker_processes auto;
worker_connections 1024;
location ~ \.php$ {
proxy_connect_timeout 60s;
proxy_send_timeout 60s;
proxy_read_timeout 60s;
}
MySQL 优化:
[mysqld]
max_connections = 200
innodb_buffer_pool_size = 1G
slow_query_log = 1
方案二:垂直扩容(快速见效)
如果优化后仍有瓶颈,考虑升级服务器配置:
- CPU 不足:增加核心数或升级到更高主频
- 内存不足:将内存提升至 4GB、8GB 或更高
- 磁盘瓶颈:从 HDD 升级到 SSD,或增加 IOPS 配额
- 带宽不足:升级到更高带宽套餐(价格截至 2026 年 4 月,以官网实时价格为准)
对于使用云服务器(基于云计算的弹性服务器)的用户,大多数平台支持在线升级配置,停机时间短,可参考 Hostease VPS 主机 了解可选配置。(配置价格因供应商和地区而异,以官网实时报价为准)
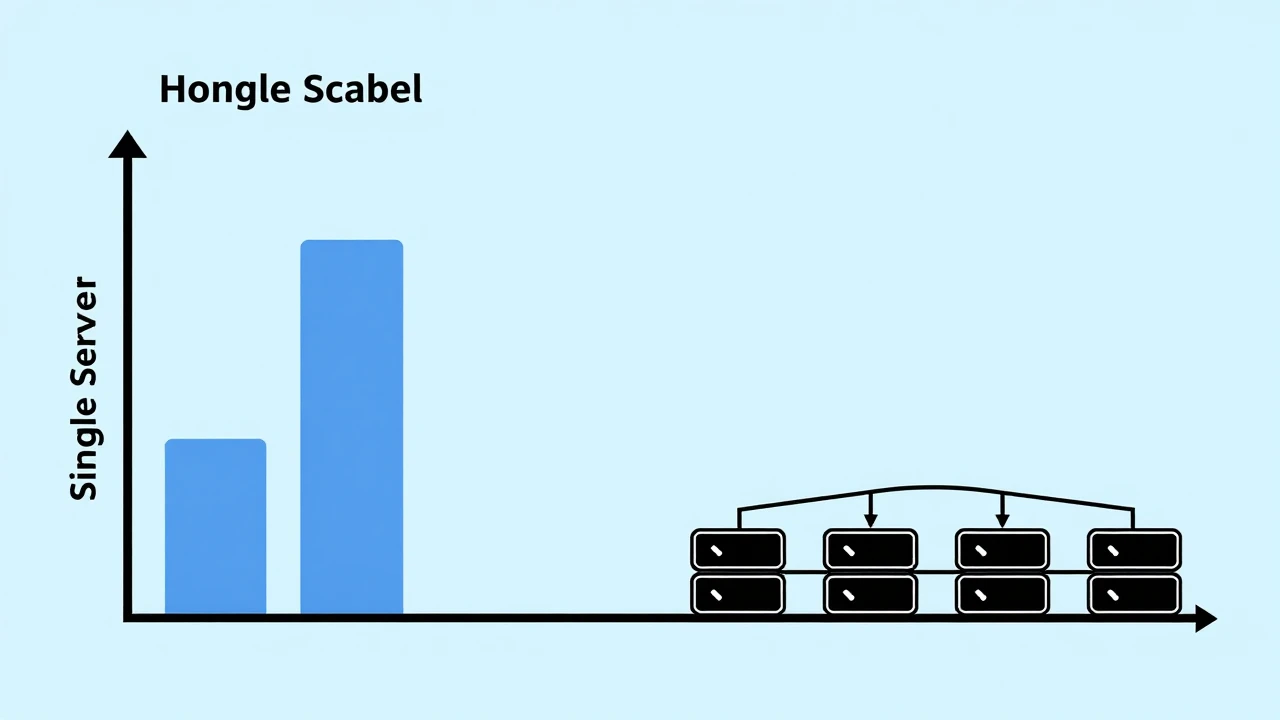
方案三:水平扩展(长期方案)
当单台服务器达到性能上限时,考虑水平扩展。数据库分离与缓存架构的设计细节可参考 VPS 与独立服务器分层部署指南:数据库分离与缓存架构:
- 负载均衡:使用 Nginx 或 HAProxy 分发流量
- 数据库分离:将 MySQL 迁移到独立服务器
- CDN 加速:将静态资源托管到 CDN(内容分发网络)
- 缓存层:引入 Redis 或 Memcached
方案四:架构优化(根本解决)
- 启用对象缓存:使用 Redis Object Cache
- 优化慢查询:分析 MySQL 慢查询日志,添加索引
- 异步处理:将耗时操作改为后台任务
- 代码审查:移除低效插件,优化主题代码
实战案例
某 WordPress 电商站每天 15:00-17:00 频繁出现 502 错误。排查发现:PHP 进程池耗尽(50/50)、内存使用 95%、MySQL 连接 180/200。解决方案:max_children 提升至 80、添加数据库索引、启用 Redis 缓存、内存 4GB→8GB。结果:502 错误消失,加载时间 3.5 秒→1.2 秒。
预防机制:持续监控与告警
建议监控 CPU、内存、磁盘 I/O、PHP-FPM 进程数、MySQL 连接数等核心指标,设置 75-80% 警告阈值、90-95% 严重阈值。工具推荐:Prometheus + Grafana(系统监控)、ELK Stack(日志分析)、Uptime Robot(简单方案)。
总结与行动建议
502 错误虽然常见,但通过系统性的日志分析和容量评估,你可以快速定位问题并采取针对性措施。我们建议的做法是:
- 立即行动:检查当前服务器日志,确认 502 错误根本原因
- 短期优化:调整 PHP-FPM、Nginx、MySQL 配置
- 中期扩容:根据容量评估结果升级硬件
- 长期规划:引入缓存层、CDN 和负载均衡
如果你需要更专业的服务器支持,可以考虑使用专业的 WordPress 主机服务。合理的架构设计和持续监控,能让你的站点稳定运行。
更多关于服务器优化和 WordPress 性能调优的内容,可以阅读我们的 服务器优化指南 和 WordPress 教程 系列文章。