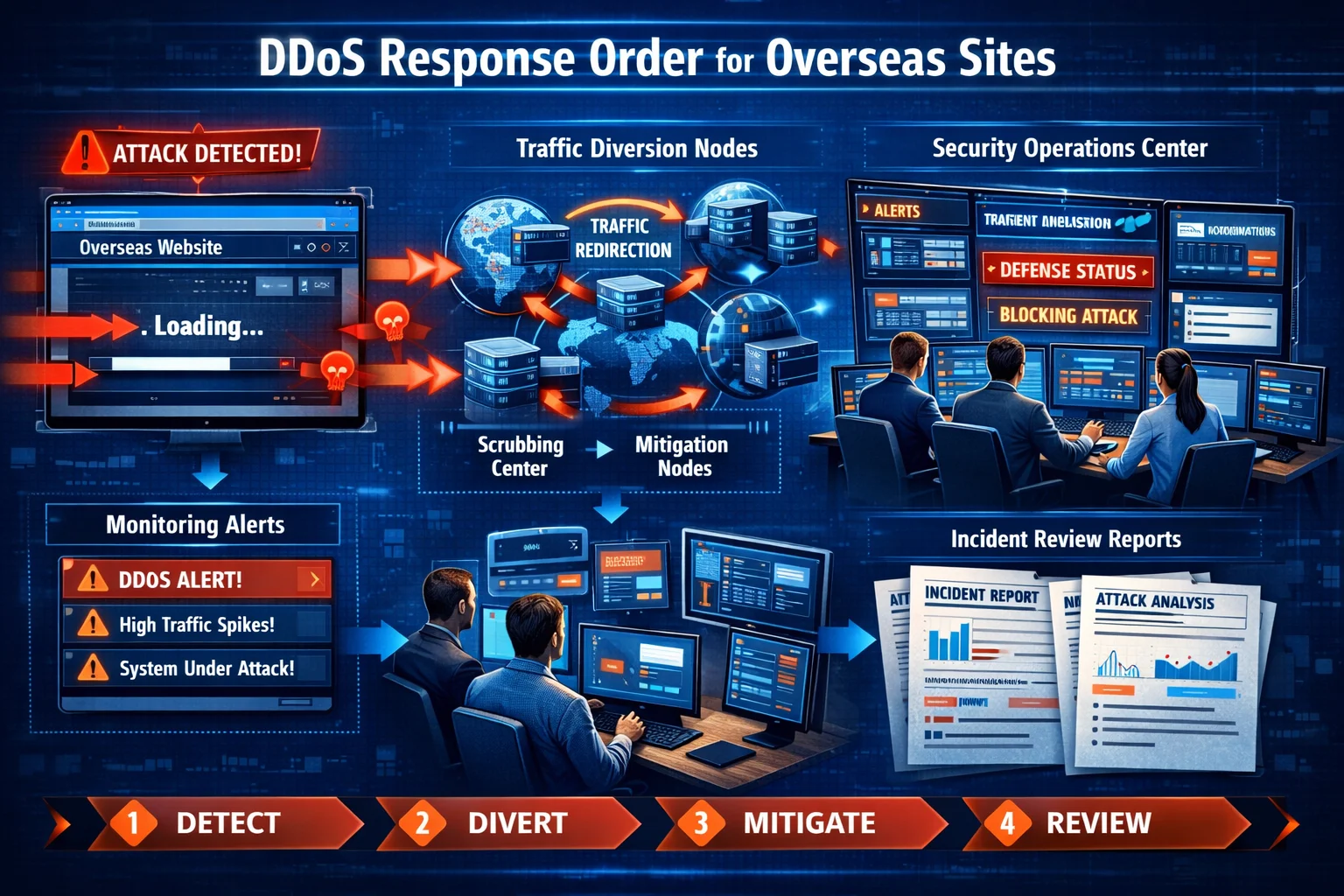
很多团队谈 DDoS 防护,第一反应都是买什么方案、配多少高防、是不是要上清洗服务。但真正出事的那一刻,最缺的往往不是概念,而是顺序。站点突然变慢、部分区域打不开、监控报警一片红时,如果团队不知道先做什么、后做什么,再好的资源也容易被浪费在混乱里。
DDoS 响应顺序之所以重要,是因为攻击发生后的前 10 到 30 分钟通常决定了损失会不会继续扩大。这个阶段最怕的不是信息少,而是动作乱:有人忙着改配置,有人忙着问服务商,有人还在试图现场分析根因,结果没有一个动作真正先把业务止血。对海外站点来说,这个问题更明显,因为节点、线路和服务商往往更分散。
也正因为如此,这篇不再重复讲 DDoS 基础概念,而是直接讲更务实的处理顺序。相关的主机与高防环境思路,可以顺带参考 HostEase 的 服务器文章。真正有用的应急方案,永远是先把动作次序排清楚。
第一步:先确认是不是 DDoS,不要一上来就乱改配置
很多故障表面上像攻击,其实也可能是源站超载、缓存失效、接口风暴或者第三方故障。响应的第一步,不是立刻大量修改配置,而是先判断:问题是局部异常还是广泛异常?入口流量是否突然陡增?是网络层卡住,还是应用层变慢?
如果连故障类型都还没分清,就贸然改 DNS、切源、关服务,很容易让原本还能留住的访问也一起掉下去。应急不是比谁反应更快,而是比谁先把判断做准。
第二步:先保住核心路径,而不是试图一次救全站
攻击发生时,最先应该保护的是最关键的业务路径。例如首页、支付页、登录页、主站静态内容,或者客户最依赖的那一部分服务。不要一开始就想“所有功能全部恢复”,那通常意味着没有优先级。
只要核心路径先稳住,团队就能争取到更多时间做分流和排查。反过来说,如果连核心路径都没先保住,却去救一些非关键功能,往往只会扩大混乱。
第三步:立刻做入口分流和限流,不要只盯源站
很多团队一遇到攻击,会下意识去看源站机器。但真正更有效的动作,通常发生在更前面:CDN、WAF、清洗节点、访问控制规则、速率限制。这些地方离流量更近,也更适合先挡掉明显异常请求。
这个阶段最务实的目标,不是彻底消灭所有攻击,而是把明显异常流量先切掉,让正常访问有机会回来。只要入口没有先分流,源站再怎么调也常常是被动挨打。
第四步:把沟通链拉直,谁负责判断、谁负责执行、谁负责对外说明
DDoS 响应经常失控,不是技术手段不够,而是沟通结构太乱。有人盯监控,有人盯服务商工单,有人修改配置,还有人对业务方说不清当前状态。没有清晰分工时,团队会不断重复确认同一件事,却很难真正推进处理。
更稳的方式是把角色先拆开:一个人负责观察和判断,一个人负责执行调整,一个人负责与服务商同步,一个人负责对业务方反馈。只要这条线清楚,整个响应会立刻有秩序得多。
第五步:攻击缓下去之后,不要立刻结束,先做快速复盘
很多团队一看到站点恢复,就以为事件结束了。实际上,这通常只是“暂时恢复访问”,不是“问题已经真正解决”。更应该紧接着做的是快速复盘:攻击从哪里开始,入口哪一层最先失守,哪些规则有效,哪些动作浪费了时间,哪些监控没有提前报出来。
只要这一步跳过,下次遇到同样问题时,团队通常还会用同样混乱的方式再来一遍。真正能提高安全韧性的,不只是多买防护,而是把每次攻击都变成下一次更快响应的材料。
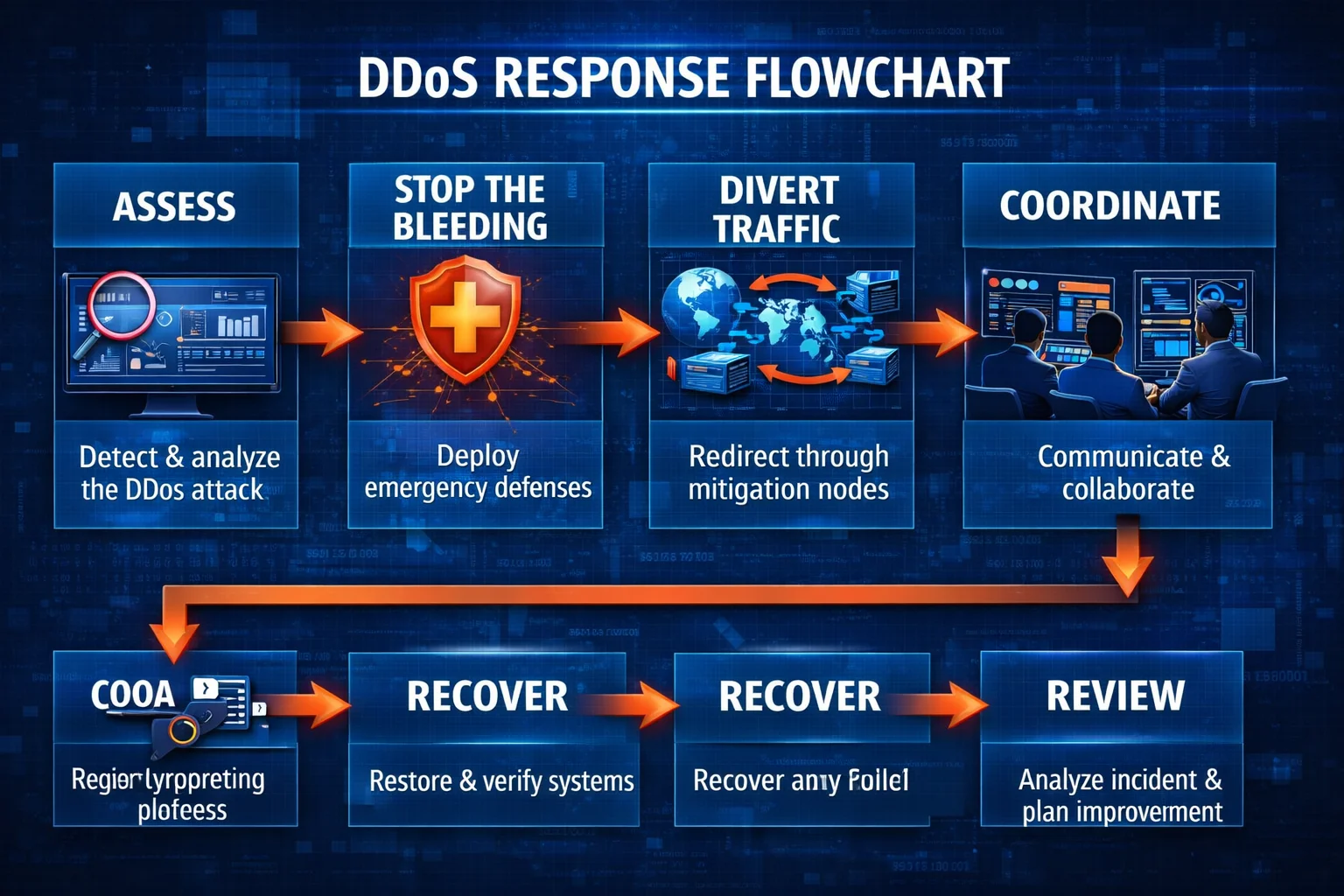
一份更务实的应急顺序,可以先记这 6 个词
判断。 先分清是不是 DDoS。
止血。 先保核心路径。
分流。 从入口层切异常流量。
协同。 拉直内部和服务商沟通线。
恢复。 逐步恢复非关键功能。
复盘。 把经验沉淀成下次可执行的 runbook。
这 6 个词看起来不复杂,但能做到的人并不多。真正的应急能力,往往就体现在这些基础动作有没有稳定执行下来。
如果团队愿意把这 6 步提前写成自己的 runbook,并配上角色分工和联系人清单,那么真正出事时的响应质量会提升很多。应急最怕靠临场发挥,而最稳的做法永远是把关键动作预先写好、演练过、确认过。
很多团队以为 runbook 只是文档工作,其实它本质上是在替最紧张的时刻节省决策成本。尤其当业务、运维和服务商需要同时协同时,一份写清楚顺序的清单,往往比临场讨论十分钟更有价值。它减少的不只是混乱,也是在减少误操作的概率。
结语:DDoS 发生时,先有顺序,比先有完美方案更重要
海外站点遇到 DDoS 时,最怕的不是完全没有资源,而是资源不少、顺序很乱。因为一旦动作没有先后,整个团队就会在焦虑里各自出手,最后却很难真正把核心业务先救回来。
所以比起再讲一遍“DDoS 是什么”,更重要的是把“发生后先做什么”写清楚。只要顺序稳住,后面的防护、扩容和复盘才真正有基础。
对海外站点来说尤其如此。因为链路更长、服务商更多、团队协同成本也更高,一旦顺序不清楚,故障时间就会被沟通和误判拉长。把顺序先写出来,本身就是一种非常实际的防御准备。
从安全成熟度角度看,真正拉开差距的也不是谁买了更多防护,而是谁能在压力最大的时刻保持动作一致。只要团队能把一次 DDoS 事件处理成一套可重复执行的流程,下次遇到类似问题时,恢复速度通常会快很多。这就是 runbook 真正的价值所在。