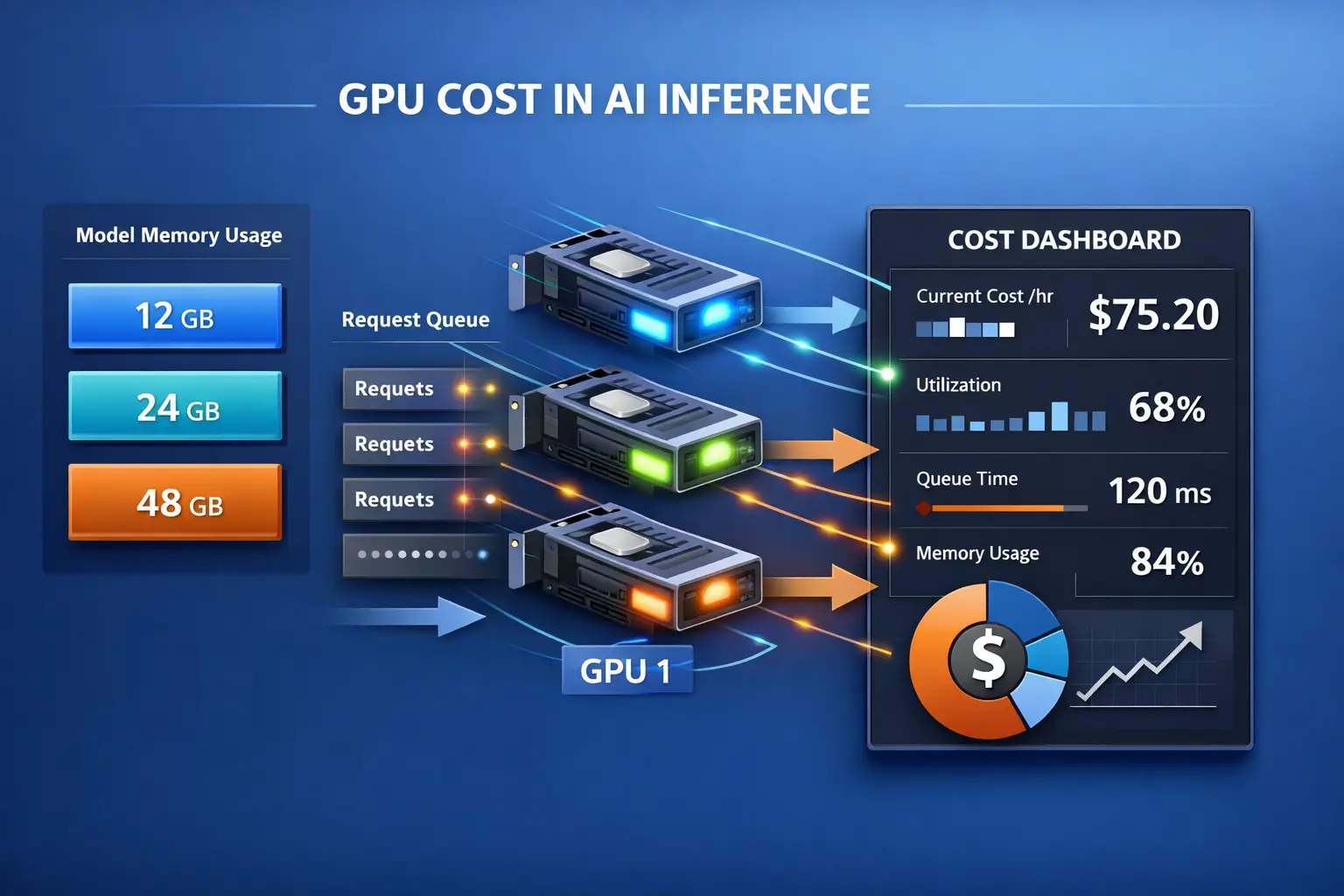
GPU



中小团队做 AI 应用,什么时候该租 GPU VPS,什么时候该上集群
中小团队做 AI 应用时,GPU VPS 和 GPU 集群并不是谁更高级的问题,而是业务阶段是否匹配。本文对比两种方案的适用条件、成本结构和升级信号。




深度学习必修课:为什么神经网络更偏爱GPU?从矩阵运算拆解张量核心(TensorCores)

我在排查训练变慢的问题时发现,神经网络真正“吃”的是矩阵乘法。GPU用海量并行把GEMM跑满,而张量核心则把A×B+C做成硬件级MMA流水线,再配合TF32/FP16/FP8混合精度稳住收敛。本文用通俗拆解原理并给出实用建议与FAQ。